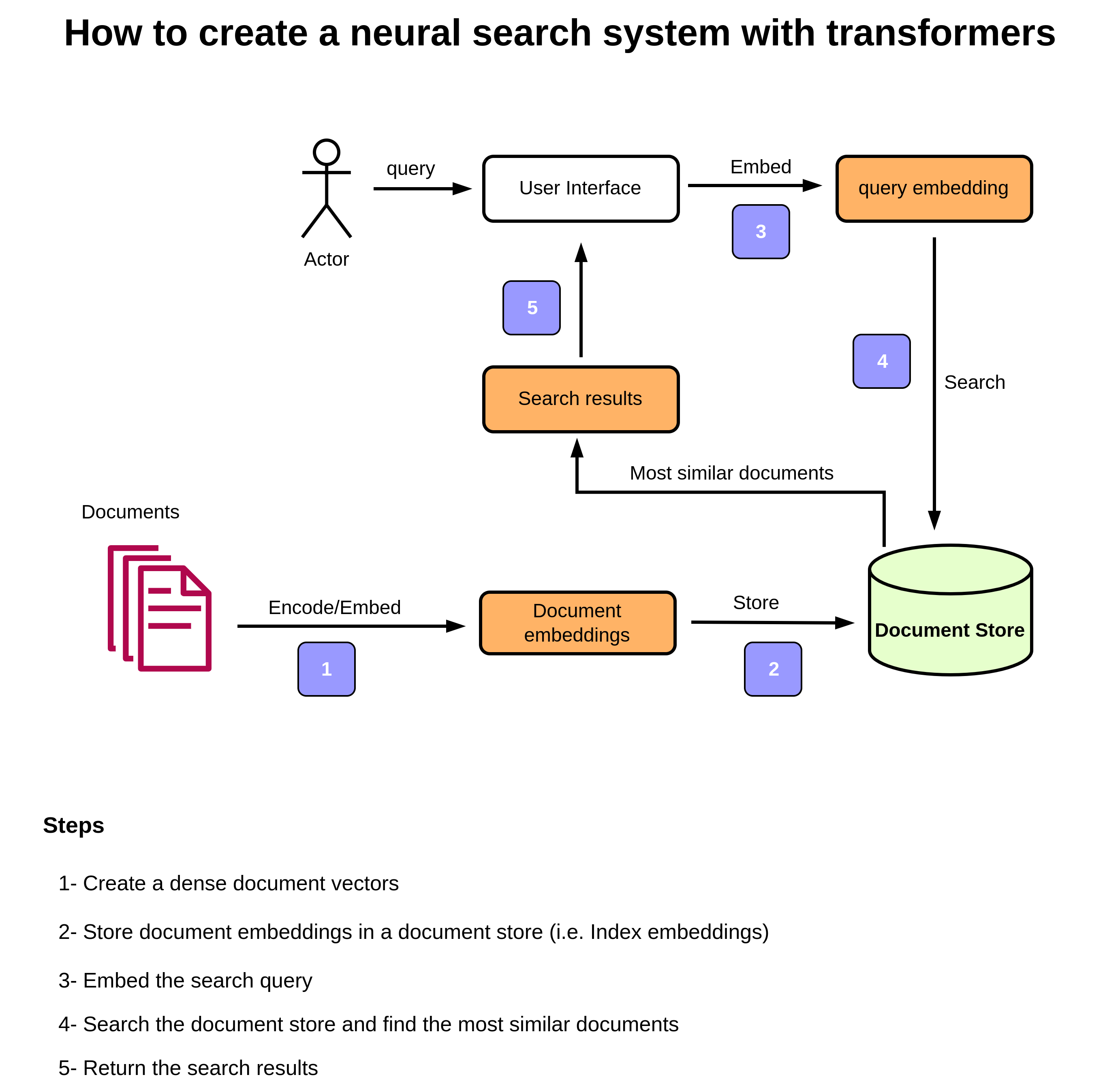
The diagram below shows the architecture of the system:
Step 0: Collect a dataset
I used a dataset that is about startups. Dataset is in json format and each record includes the name, a paragraph describing the company, the location and a picture. The dataset is available at this link.
df = pd.read_json("https://storage.googleapis.com/generall-shared-data/startups_demo.json", lines=True)
df.head(3)
We only implement a search mechanism on the description column, i.e. we search and find similar companies based on the similarity of the search query and descriptions.
corpus = df.description.tolist()
print(f"Total number of documents: {len(corpus)}")
Step 1: Create dense vectors of documents (i.e. document embeddings).
We need to have an embedding model to create embeddings of our text documents. We use a pretrained language model from the Sentence Transformers, specifically we utilize all-distilroberta-v1 model as it works very well for semantic search applications.
# Instantiate the model. You can set the device to `cpu` if don't have access to `gpu`.
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1', device='cuda')
# convert documents into embeddings
corpus_embeddings = model.encode(corpus, show_progress_bar=False)
Step 2: Store the embeddings or index the embeddings
In order to be able to perform search and find documents, we need to store document embeddings in a document store. In other words, we have to index them. There are several different ways to do that, nevertheless, I work with Faiss for now.
Faiss allows us to search through billions of vectors very efficiently. For complete information about Faiss, please check their wiki page or read their paper.
Faiss is built around the Index object, which contains searchable vectors. Faiss handles collections of vectors of a fixed dimensionality d, typically a few 10s to 100s.
Faiss uses only 32-bit floating point matrices. This means we will have to change the data type of the input before building the index.
# Convert the data type of the embeddings into float32.
corpus_embeddings = np.array([embedding for embedding in corpus_embeddings]).astype("float32")
corpus_embeddings.shape
# Build the index. Shape of embeddings is (40474, 768), so we set the dimension of index to 768.
index = faiss.IndexFlatL2(corpus_embeddings.shape[1])
# Add the document vectors into the index
index.add(corpus_embeddings)
search_query = "smart devices"
# Embed the query
query_embedding = model.encode([search_query])
# We're interested in top-5 most similar documents
top_k = 5
# Search function returns two arrays, Distances of the nearest neighbors with shape (n, k), and Labels/ids of the nearest neighbors with shape (n, k).
distances, ids = index.search(np.array(query_embedding), k=top_k)
print(distances, ids)
for i in range(len(ids[0])):
print(f"----------------------------------- Similar document {i + 1} -------------------------------------------")
print(corpus[ids[0][i]])
print()
Next Steps
So far, we have implemented a search engine using Faiss fairly simply. However, There are several directions for improvement.
- Firstly,
IndexFlatL2index that we used could be slow for very large datasets as it scales linearly with the number of indexed vectors. That said, Faiss provides fast indexes. - Secondly, we can enhance the quality of the embeddings by using a domain specific pretrained model, which could result in better and more accuarate search results.
- Thirdly, is it possible to dynamically exclude vectors based on some criterion? What I mean is, what if we would like to search our documents based on some filters, for instance, only search among the companies that are in a specific city. In these cases, there is no easy solution if we want to make use of Faiss index. Therefore, what is the solution? The answer is to apply other approaches. These approaches are, to name a few:
I will create several other examples using these packages and compare them.