Transformer revolves around the idea of a model that uses attention to increase the speed with which it can be trained. The primary motivation for designing a transformer was to enable parallel processing of the words in the sentences, i.e. to process the entire sentence at once. This parallel processing is not possible in LSTMs or RNNs or GRUs as they take words of the input sentence one by one. The first transformer was proposed in the paper Attention is All You Need. There is a TensorFlow implementation of it is available here. Also, Harvard’s NLP group provided a guide annotating the paper with PyTorch implementation. These transformer models come in different shapes, sizes, and architectures and have their own ways of accepting input data: via tokenization.
BERT Overview
BERT (Bidirectionnal Encoder Representations for Transformers) is a “new method of pre-training language representations” developed by Google in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding and released in late 2018. Since it is pre-trained on generic large datasets (from Wikipedia and BooksCorpus), it can be used for a wide variety of NLP tasks like text classification, translation, summarization, and question answering. Here is the abstract from the paper:
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
BERT provides pre-trained language models for English and 103 other languages that you can fine-tune to fit your needs. Fine-tuning a model means that we will slightly train it using our dataset on top of an already trained checkpoint. Here, we’ll see how to fine-tune the multilingual model to do sentiment analysis. To do that, we follow the steps below:
Load and preprocess the data so that it can be used by the model.
Set-up a training loop using Keras' fit API; train the model on the training data
Evaluate the model on the testing data and compare to the actual results
Sentiment Analysis on Farsi Text
The following implementation shows how to use the Transformers library to obtain state-of-the-art results on the sequence classification task. This library "provides general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch".
There are plenty of applications of classification on English text. Thus, the goal of my implementation is to perform sentiment classification on non-English text, in this case Farsi(Persian) language. As it takes time to run it on CPU, I created a Google Colab notebook version of the entire implementation, which you can access it here.
Load the data
For this tutorial, I used a Farsi dataset, from Kaggle. It contains over 68000 comments about books gathered from a book website called taaghche.
# Remove the unnecessary columns
df = df.drop(columns=['date', 'bookname', 'bookID', 'like'])
# df = df.rename(columns={'Text':'text','Suggestion': 'label'})
df.loc[(df.rate < 3), 'label'] = '0'
df.loc[(df.rate >= 3), 'label'] = '1'
df = df.drop(columns=['rate'])
df.head()
df_pos = df.loc[df.label == '1']
df_neg = df.loc[df.label == '0']
print('Postive examples: {} Negative examples: {}'.format(len(df_pos),len(df_neg)))
dataset_size = 5000
dataset = create_small_dataset(df_pos, df_neg, dataset_size)
#shuffle the dataset
dataset = dataset.sample(frac=1).reset_index(drop=True)
dataset
train_data, test_data = train_test_split(dataset, test_size=0.2)
print('train data size: {} test data size: {}'.format(len(train_data), len(test_data)))
Convert the Data into Bert Specific Format
We need to transform our data into a format BERT understands. This involves two steps. First, we create a list of InputExample objects using the constructor provided by Transformers library. Every InputExample must have the following structure:
text_ais the text we want to classifytext_bis used if we're training a model to understand the relationship between sentences (i.e. istext_ba translation oftext_a)? Istext_ban answer to the question asked bytext_a?). This doesn't apply to our task, so we can leavetext_bblank.labelis the label of our example, i.e. True or False.
train_input_examples = convert_data_into_input_example(train_data)
val_input_examples = convert_data_into_input_example(test_data)
Next, we need to preprocess our data (i.e. InputExample's) so that it matches the data BERT was trained on. Therefore, we need to do a few things:
Lowercase our text (if we're using a BERT lowercase model)
Tokenize it (i.e. "sally says hi" -> ["sally", "says", "hi"])
Break words into WordPieces (i.e. "calling" -> ["call", "##ing"])
Map our words to indexes using a vocab file that BERT provides
Add special "CLS" and "SEP" tokens (see the readme)
Append "index" and "segment" tokens to each input (see the BERT paper)
Tokenization
Deep learning models accept certain kinds of inputs, which is vectors of integers, each value representing a token. Each string of text must first be converted to a list of indices to be fed to the model. The tokenizer takes care of that for us. We also need to add special tokens to the list of ids.
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased', do_lower_case=False)
text = 'I liked that book very much!'
tokenized_text = tokenizer.tokenize(text)
print(tokenized_text)
text_ids = tokenizer.convert_tokens_to_ids(tokenized_text)
print('text ids:', text_ids)
text_ids_with_special_tokens = tokenizer.build_inputs_with_special_tokens(text_ids)
print('text ids with special tokens: ', text_ids_with_special_tokens)
Happily, there is a much simpler method that can do all the previous steps (i.e. tokenize, convert to indices and add special tokens) altogether.
MAX_SEQ_LENGTH = 128
encoded_bert_text = tokenizer.encode(text, add_special_tokens=True, max_length=MAX_SEQ_LENGTH)
# encoded_bert_text = tokenizer.encode(text, add_special_tokens=True, max_length=MAX_SEQ_LENGTH, return_tensors='tf')
print('encoded text: ', encoded_bert_text)
decoded_text_with_special_token = tokenizer.decode(encoded_bert_text)
decoded_text_without_special_token = tokenizer.decode(encoded_bert_text, skip_special_tokens=True)
print('decoded text with special token: ', decoded_text_with_special_token)
print('decoded text without special token: ', decoded_text_without_special_token)
However, we still require other addtional information to deal and manage. Thankfully, the Transformer library has a method to directly convert a dataset of InputExamples into features BERT understands. This method is called glue_convert_examples_to_features.
label_list = ['0', '1']
bert_train_dataset = glue_convert_examples_to_features(examples=train_input_examples, tokenizer=tokenizer, max_length=MAX_SEQ_LENGTH, task='mrpc', label_list=label_list)
bert_val_dataset = glue_convert_examples_to_features(examples=val_input_examples, tokenizer=tokenizer, max_length=MAX_SEQ_LENGTH, task='mrpc', label_list=label_list)
for i in range(3):
# print('Example: {}'.format(bert_train_dataset[i]))
print('Example: {')
print(' Input_ids: {}'.format(bert_train_dataset[i].input_ids))
print(' attention_mask: {}'.format(bert_train_dataset[i].attention_mask))
print(' token_type_ids: {}'.format(bert_train_dataset[i].token_type_ids))
print(' label: {}'.format(bert_train_dataset[i].label))
print('}')
# Let's take a look at one example from the dataset
ex = bert_train_dataset[0]
in_ids = ex.input_ids
decoded_sentence = tokenizer.decode(in_ids, skip_special_tokens=True)
print(decoded_sentence)
model = TFBertForSequenceClassification.from_pretrained('bert-base-multilingual-cased')
optimizer = tf.keras.optimizers.Adam(learning_rate=2e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
bert_train_dataset, (which is supposed to work), to the model.fit() did NOT work, so I had to workaround it.# This way did NOT work, so I had to workaround it.
model.fit(bert_train_dataset, validation_data=bert_val_dataset, epochs=3)
Workaround
I used the bert_train_dataset and created a list for each feature (i.e. input_ids, attention_mask, token_type_ids and label) and passed them as the arguments of the model. Please see transformers' documentation for more details.
x_train, y_train = my_solution(bert_train_dataset)
x_val, y_val = my_solution(bert_val_dataset)
print('x_train shape: {}'.format(x_train[0].shape))
print('x_val shape: {}'.format(x_val[0].shape))
train_ds = tf.data.Dataset.from_tensor_slices((x_train[0], x_train[1], x_train[2], y_train)).map(example_to_features).shuffle(100).batch(32)
val_ds = tf.data.Dataset.from_tensor_slices((x_val[0], x_val[1], x_val[2], y_val)).map(example_to_features).batch(64)
print('Format of model input examples: {} '.format(train_ds.take(1)))
EPOCHS = 5
history = model.fit(train_ds, validation_data=val_ds, epochs=EPOCHS)
Training Details
Epoch 1/5
250/250 [==============================] - 137s 548ms/step - loss: 0.5838 - accuracy: 0.6894 - val_loss: 0.5079 - val_accuracy: 0.7665
Epoch 2/5
250/250 [==============================] - 134s 535ms/step - loss: 0.4867 - accuracy: 0.7747 - val_loss: 0.5002 - val_accuracy: 0.7650
Epoch 3/5
250/250 [==============================] - 134s 534ms/step - loss: 0.4131 - accuracy: 0.8227 - val_loss: 0.5112 - val_accuracy: 0.7685
Epoch 4/5
250/250 [==============================] - 134s 534ms/step - loss: 0.3515 - accuracy: 0.8558 - val_loss: 0.5692 - val_accuracy: 0.7630
Epoch 5/5
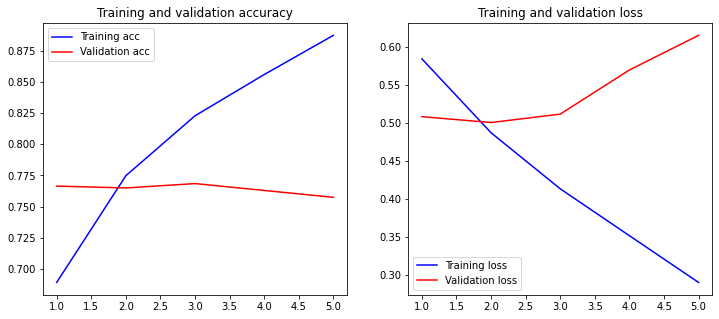
250/250 [==============================] - 134s 535ms/step - loss: 0.2901 - accuracy: 0.8871 - val_loss: 0.6147 - val_accuracy: 0.7575plot_history(history)
Plot the Loss and Accuracy
We can see the training and validation loss as well as accuracy in the plots below. Please note that after epoch 3 validation loss starts to grow, which means the model begins to overfit. Therefore 3 epochs would be enough and work better since it has better accuracy of 0.7685.
predictions = model.predict(val_ds)
print(predictions[0].shape)
print()
predictions_classes = np.argmax(predictions[0], axis = 1)
for i in range(10):
print('comment: {}\n, actual label: {}, predicted label: {}'.format(test_data.iloc[i]['comment'], val_input_examples[i].label, predictions_classes[i]))
comment: کسالت آور بود
ولی چون یک داستان نسباتا واقعیست ، به خاطر حقایقی که در اون وجود داشت بخوبی ما رو با فرهنگ و اعتقادات مردم اون دوره انگلیس آشنا میکنه
داستان کشتی تایتانیک
, actual label: 0, predicted label: 1
comment: شیوایی کلام میتوانست بهتر باشد
, actual label: 0, predicted label: 0
comment: باسلام،برای قشرخاصی طراحی شده کتاب ودرکش برای عموم کمی سخت وگیج کننده است
, actual label: 0, predicted label: 1
comment: بد نبود- راضی کننده بود
, actual label: 1, predicted label: 0
comment: من به عنوان یه نویسنده این مجله تقاضا میکنم همه ازش حمایت کنند! این یه کار نمونه ای علمی ترویجی نو تو زمینه زبان کوردی هست و نیاز به حمایت همه داره
, actual label: 1, predicted label: 0
comment: دوستشدارمدوستش خواهی داشت✌
, actual label: 1, predicted label: 0
comment: خیلی قشنگ بود
مرسی طاقچه جون
, actual label: 0, predicted label: 1
comment: همه کتاب داره درباره جزییات ظاهر بقیه و محیط صحبت میکنهچنگی ب دل نمیزنهبسیار خسته کنندس
, actual label: 0, predicted label: 0
comment: کتاب رو خوندم
به نظرم کتاب مفیدی میتونه باشه
فقط طیق معمول کتب روانشناسی داستان زیاد داره
خودم فقط قسمتهای غیر داستانی رو خوندم اگر ابهام ایجاد میشد داستانش رو هم میخوندم
کلا خوبه
حداقل متوجه میشید زبان عشق خودتون چیه و ب طرف مقابلتون میتوتید بگید با من اینطوری باش
, actual label: 1, predicted label: 1
comment: کتاب با بررسی وقایع کربلا و تطبیق آنها با زندگی امروز به ما هشدار میدهد تا به سمت همان فرهنگی که فرزند رسول خدا را به شهادت رساند حرکت نکنیم و این کار را با دلایل منطقی و بسیار هوشمندانه انجام داده است
پیشنهاد میکنم این کتاب رو حتماً بخونید چون جواب بسیاری از سوالاتتون رو خواهید گرفت
, actual label: 1, predicted label: 1# pred_sentences = ['به نظر کتاب خوبی نمی ومد', ' رایگان بودنش فوق العادش میکند']
pred_sentences = [comment for comment,l in test_data.sample(20).values]
predictions = get_prediction(pred_sentences)
for p in predictions:
print(p)
('واقعا چطور همچین کتابایی اجازه نشر پیدا میکنن؟', 0)
('روش چی ؟', 0)
('بنظرم کتاب زندگینامه شهید رو رایگان کردن صورت خوشی نداره! چون اونی که براش مهمه بخونه پولشو میده میخره کسی هم که سلیقه مطالعه کتابش این مدلی نیست، رایگانم بشه نمیخونه', 0)
('سوالات کجا میاد کجا باید جواب بدیم', 0)
('سمنوپزان ، مسلول و زن زیادی خوب بودند ؛ در کل ادم رو به گذشته های دور و شیوه زندگی اونها میبره و از این جهت فوق العاده است\nممنون از طاقچه بابت برنامه خوبش و به خاطر کتابهایی که رایگان کردید', 1)
('کتاب فوق العاده ای بود به خیلی از شبهات در غالب داستان جواب داده حتما پیشنهاد میکنم', 1)
('چقدر قشنگ بالا و پایین زندگی رو نشون داده بود ', 0)
('ترجمه اش اصلا خوب نیست', 0)
('واقعا این کتاب عالییییییییییییییییییییییییییییییییییییییییییییییییه یه حرف نگفته اس که غمباد شده تو دلمون واقعا دست مریزاد سرکاره خانوم عالیشاهی با آرزوی بهترین ها و بالاترین درجات برای شما نویسنده محترمه', 1)
('واقعاً قیمت ها رو بر چه اساس تعیین میکنید نمیدونم قیمت نسخه چاپی ۵۰ تومان هست که با توجه به قیمت کاغذ منطقی هست اما نسخه الکترونیک برای یک کتاب نباید انقدر گران باشد بنظرم طاقچه باید محدودیت های مشخص شده قرار بده برای قیمت', 0)
('واقعا صداش خوب نیست چون انگار داره برا بچه ها قصه میگه همچین متن هایی رو باید یه نفر با صدای قوی ومحکم وبا جذبه قرائت کنه ', 0)
('خیلی داستان جذابی نداشت و در آخر داستان هم\u200c اسلام هراسی بیداد میکرد', 0)
('سلام من این کتاب را قبلا خریداری کردم نمی دانم چرا الان فایل کتاب را باز نمی کند ؟', 0)
('آیا حرف دلواپسان درست نبود؟', 0)
('عالی', 1)
('کتاب سطح پایین با نثری درهم پیچیده البته ترجمه نامناسب', 0)
('قشنگ بود', 1)
('ترجمه خیلی خیلی خیلی بد و غیرقابل فهم', 0)
('یکی از بهترین و ساده ترین کتاب ها برای کسایی که دنبال راه حلی هستند تا در زندگی مالی موفق شوند', 1)
('خیلی عالی بود لذت بردم امیدوارم شما هم فراموش نکنید اولین نفری بودم که به ازادیش فکر کردم به درخت، به ماهی، به دلیران تنگسیر، به پایانی خوش', 1)print("Evaluating the BERT model")
model.evaluate(val_ds)
Evaluating the BERT model
32/32 [==============================] - 9s 293ms/step - loss: 0.6147 - accuracy: 0.7575
[0.6146795749664307, 0.7574999928474426]