What is TF-IDF?
TF-IDF stands for "Term Frequency — Inverse Document Frequency". It is a statistical technique that quantifies the importance of a word in a document based on how often it appears in that document and a given collection of documents (corpus). The intuition for this measure is : If a word occurs frequently in a document, then it should be more important and relevant than other words that appear fewer times and we should give that word a high score (TF). But if a word appears many times in a document but also in too many other documents, it’s probably not a relevant and meaningful word, therefore we should assign a lower score to that word (IDF). The relevancy of a word is proportional to the amount of information that it gives about its context (a sentence, a document or a full dataset). The more relevant words help us better understand the entire document without reading it completely. The most relevant words are not necessary the most frequent words since stopwords like "the", "of" or "a" tend to occur very often in many documents, but do not give much information. TF-IDF method is widely used in Information Retrieval and Text Mining. The TF-IDF score of term $t$ in document $d$ with respect to corpus $D$ is:
$$tfidf(t,d,D)=tf(t,d)\times idf(d,D)$$
Term Frequency (TF) Score
First we have to calculate the $tf(t,d)$, which is simply the number of times each word $t$ appeared in document $d$. While calculating $tf(t,d)$, we usually remove words like "a", "as", "the". These words are called stopwords and will not provide much information. Additionally, there could be many high frequency non-stopwords that do not provide much information in a given context (e.g., “Disney” in a collection of documents about “Disney World”), Therefore, we can filter them out too. Also, we normalize the term-frequency to make sure there is no bias for longer or shorter documents. Thus, we have:
$$tf(t,d)=\frac{f_{t,d}}{\sum_{t'} f_{t',d}}$$
where $f_{t,d}$ is the number of occurances of $t$ in $d$.
Inverse Document Frequency (IDF)
It measures how rare a term $t$ is across the corpus $D$, meaning how much information it provides about a document it appears in. If total number of documents in the corpus is $N=|D|$, and $n_t$ is the number of documents having $t$, then we have:
$$idf(t,D)=\log(\frac{N}{n_t})$$
The reason that we take the $\log$ of IDF is that if we have a large corpus, the IDF values will become so large, therefore, we use the $\log$ value to decrease that effect.
TF-IDF Example
In order to fully understand how TF-IDF works, I will give you a concrete example. Let's assume that we have a collection of four documents as follows:
$d_1$: "The sky is blue.
$d_2$: "The sun is bright today."
$d_3$: "The sun in the sky is bright."
$d_4$: "We can see the shining sun, the bright sun."
Task: Determine the tf-idf scores for each term in each document.
Step1: Filter out the stopwords. After removing the stopwords, we have
$d_1$: "sky blue
$d_2$: "sun bright today"
$d_3$: "sun sky bright"
$d_4$: "can see shining sun bright sun"
Step2: Compute TF, therefore, we find document-word matrix and then normalize the rows to sum to 1.
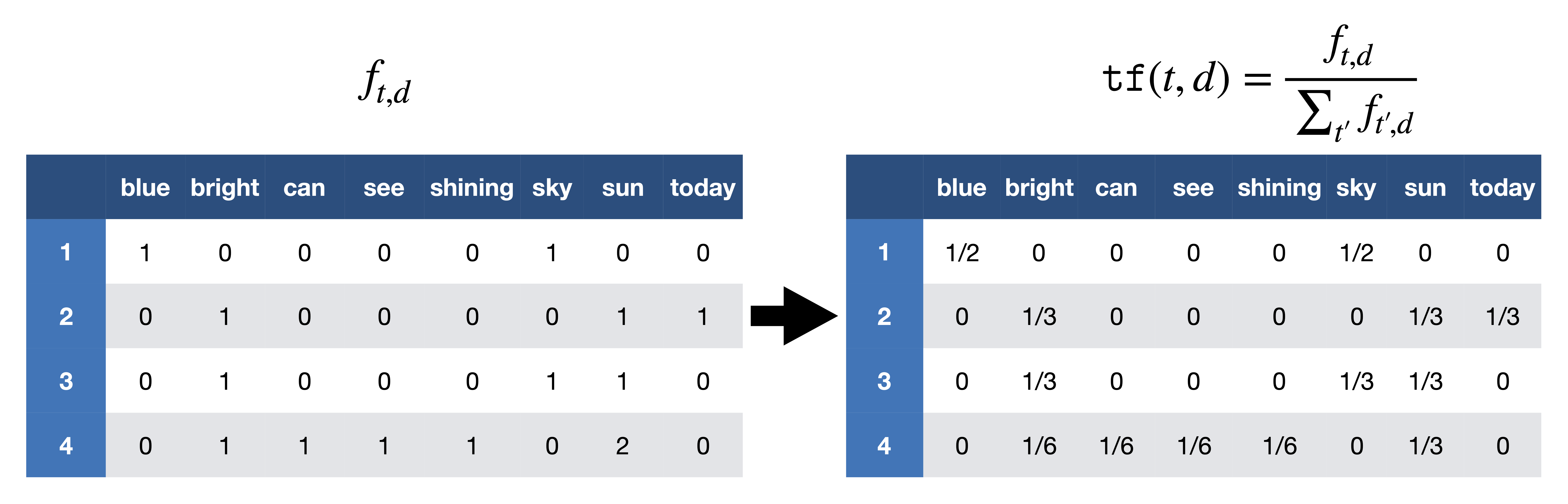 TF score computation. [Image Source]
TF score computation. [Image Source]
- Step3: Compute IDF: Find the number of documents in which each word occurs, then compute the formula:
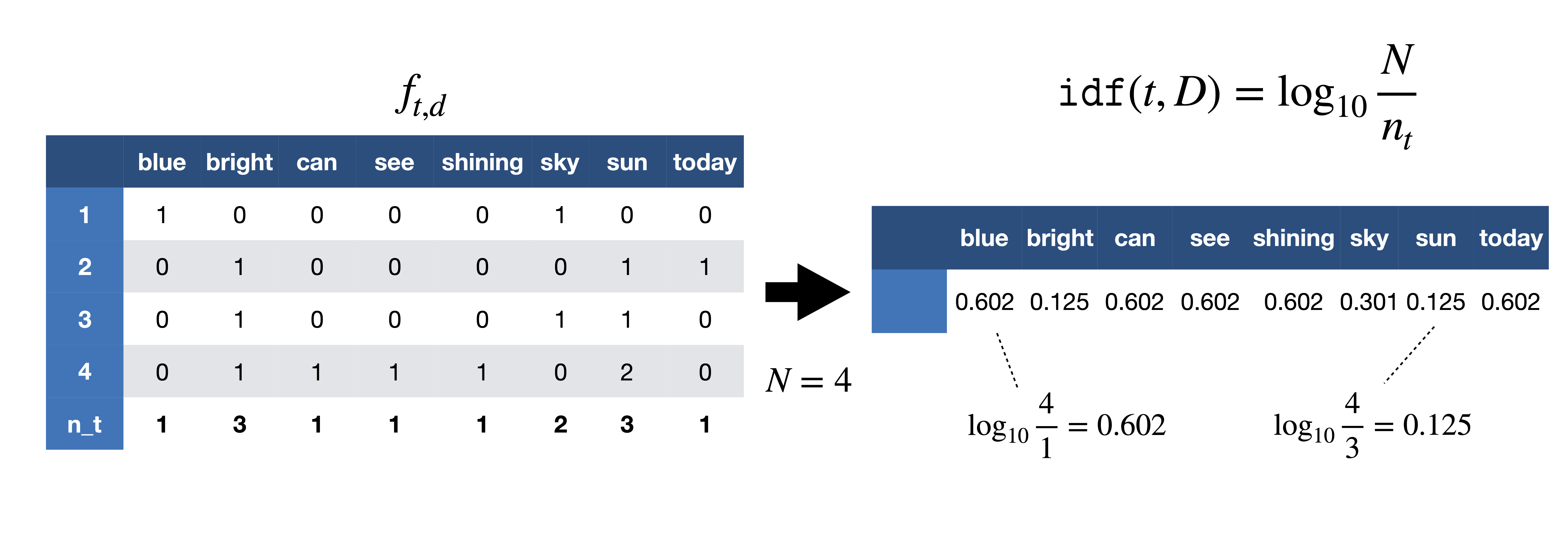 IDF score computation. [Image Source]
IDF score computation. [Image Source]
- Step4: Compute TF-IDF: Multiply TF and IDF scores.
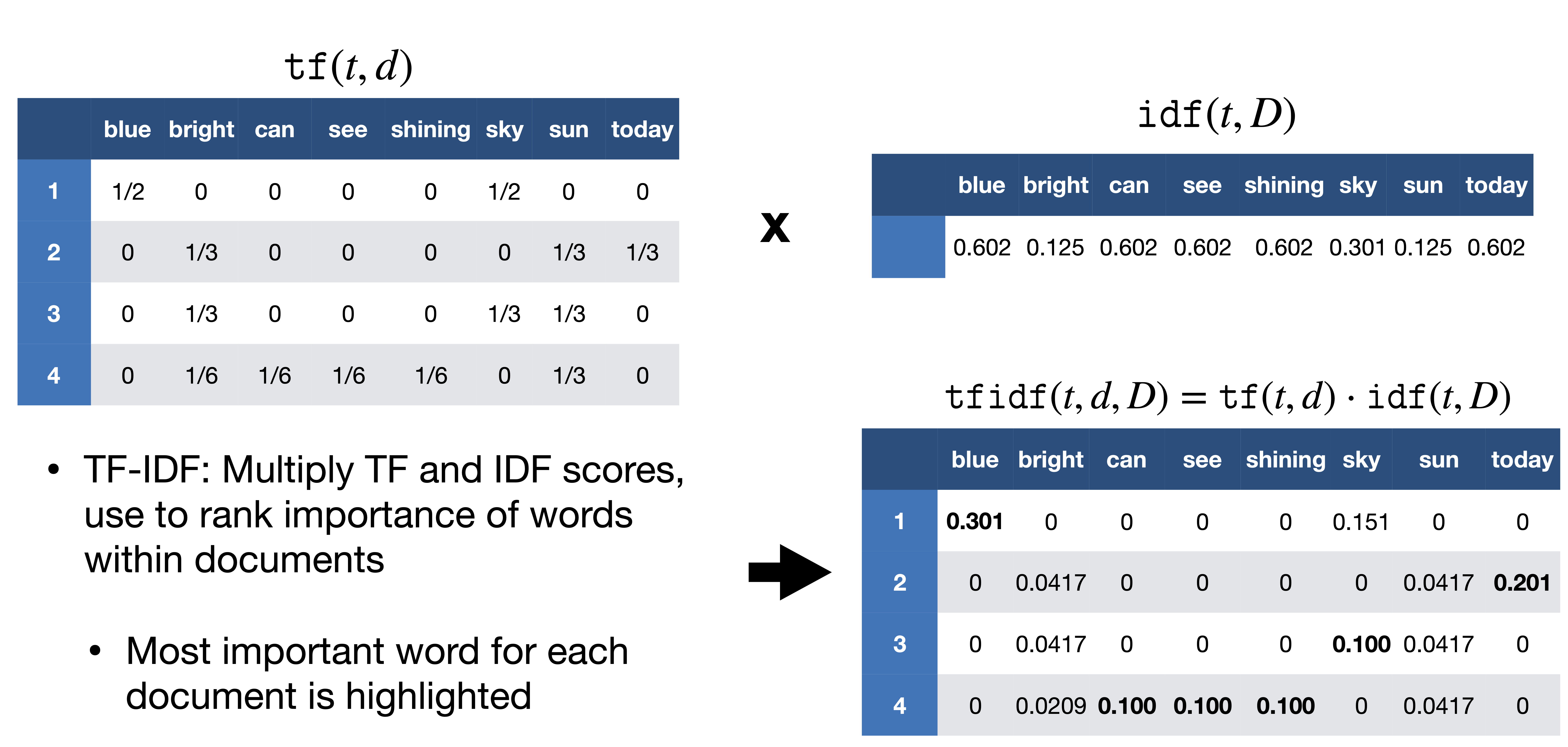 TF-IDF score computation. [Image Source]
TF-IDF score computation. [Image Source]
Application of tf-idf for Searching Text
In order to understand how to use tf-idf, I am going to make use of this technique in a text searching application. I will use a dataset of Python questions and answers from Stackoverflow. The dataset contains all the questions (around 700,000) asked between August 2, 2008 and Ocotober 19, 2016. Please see the link for all the details about this dataset. For this application, I only use the Python questions. However, it would be an interesting exercise to create a question-answering application. Each question in this file contains title and body among other attributes. But I will merely use these two fields from each question in the file.
import os
import re
import time
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
First step is to read and load the questions.csv file. Please note that it may take several seconds to fully load the file due to large number of records (607282 questions) in the file.
# Reading the csv file of python Questions
FILE_PATH = os.path.join('data','stackoverflow','Questions.csv')
print('Reading the Questions file...')
df = pd.read_csv(FILE_PATH, delimiter=',', encoding='ISO-8859-1')
print('done')
df.head()
Let's take a look at a randomly selected question.
sample_index = np.random.randint(len(df))
sample = df.loc[sample_index,['Title', 'Body']]
print('title: {}, \nbody: {}'.format(sample['Title'],sample['Body']))
Preprocessing is one of the major steps when we are dealing with any kind of text models. As you can see above, the body of the question, it's true for all the questions, has plently of html tags and special characters. Therefore, we need to get rid of them as much as we can. The preprocess() function will carry out cleaning of the questions by removing html tags, special characters and digits. As usual, there is always room for improvements by adding more cleaning rules such as stemming, lematization, stop words removal, etc.
# Preprocess the corpus
data = [preprocess(title, body) for title, body in zip(df['Title'], df['Body'])]
After we load and clean the data, it's time to create the term-document matrix. We can write simple functions for computing tf (term frequency) and idf (inverse document frequency). However, I leave this out as an interesting exercise. Instead I'll be using sklearn TfidfVectorizer to compute the word counts, idf and tf-idf values all at once. You can find all the details about TfidfVectorizer here. I would like to mention that in create_tfidf_features() function, I restrict the size of the vocabulary (i.e. number of features) to 5000 to make the computations cheaper.
print('creating tfidf matrix...')
# Learn vocabulary and idf, return term-document matrix
X,v = create_tfidf_features(data)
features = v.get_feature_names()
len(features)
Now it's time to test and see how our application works. We can ask an arbitrary question and see if the system can find the top-k most similar questions from the dataset to our question.
user_question = ['how to loop over files in a directory']
search_start = time.time()
sim_vecs, cosine_similarities = calculate_similarity(X, v, user_question)
search_time = time.time() - search_start
print("search time: {:.2f} ms".format(search_time * 1000))
print()
show_similar_documents(data, cosine_similarities, sim_vecs)
How to Use Elasticsearch for Indexing and Retrieving Text
What is Elasticsearch?
Elasticsearch is an open source distributed, RESTful search and analytics engine. Elasticsearch enables us to index, search, and analyze data at large scale. It provides real-time search and analytics for various types of data including structured or unstructured text, numerical data, or geospatial data. Elasticsearch can efficiently store and index it in a way that supports fast searches. In order to learn Elasticsearch please see the documentation. It is out of the scope of this tutorial, so I leave it as an exercise to understand and learn how Elasticsearch works.
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
import json
import time
INDEX_NAME = 'python_questions'
es_client = Elasticsearch()
create_index(es_client)
index_data(es_client, data)
SEARCH_SIZE = 3
run_query_loop()